
These days, everyone talks about open-source. However, this is still not common in the Data Warehouse (DWH) field. Why is this?
In my recent blog, I researched OLAP technologies, for this post I chose some open-source technologies and used them together to build a full data architecture for a Data Warehouse system.
I went with Apache Druid for data storage, Apache Superset for querying and Apache Airflow as a task orchestrator.
Druid - the data store
Druid is an open-source, column-oriented, distributed data store written in Java. It’s designed to quickly ingest massive quantities of event data, and provide low-latency queries on top of the data.

Why Druid?
Druid has many key features, including sub-second OLAP queries, real-time streaming ingestion, scalability, and cost-effectiveness.
With the comparison of modern OLAP Technologies in mind, I chose Druid over ClickHouse, Pinot and Apache Kylin. Recently, Microsoft announced they will add Druid to their Azure HDInsight 4.0.
Why not Druid?
Carter Shanklin wrote a detailed post about Druid’s limitations at Horthonwork.com. The main issue is with its support for SQL joins, and advanced SQL capabilities.
The Architecture of Druid
Druid is scalable due to its cluster architecture. You have three different node types — the Middle-Manager-Node, the Historical Node and the Broker.
The great thing is that you can add as many nodes as you want in the specific area that fits best for you. If you have many queries to run, you can add more Brokers. Or, if a lot of data needs to be batch-ingested, you would add middle managers and so on.
A simple architecture is shown below. You can read more about Druid’s design here.

Apache Superset – the UI
The easiest way to query against Druid is through a lightweight, open-source tool called Apache Superset. It is easy to use and has all common chart types like Bubble Chart, Word Count, Heatmaps, Boxplot and many more.
Druid provides a Rest-API, and in the newest version also a SQL Query API. This makes it easy to use with any tool, whether it is standard SQL, any existing BI-tool or a custom application.
Apache Airflow - the Orchestrator
As mentioned in Orchestrators — Scheduling and monitor workflows, this is one of the most critical decisions.
In the past, ETL tools like Microsoft SQL Server Integration Services (SSIS) and others were widely used. They were where your data transformation, cleaning and normalisation took place.
In more modern architectures, these tools aren’t enough anymore. Moreover, code and data transformation logic are much more valuable to other data-savvy people in the company.
I highly recommend you read a blog post from Maxime Beauchemin about Functional Data Engineering — a modern paradigm for batch data processing. This goes much deeper into how modern data pipelines should be.
Why using Airflow?
Apache Airflow is a very popular tool for this task orchestration. Airflow is written in Python. Tasks are written as Directed Acyclic Graphs (DAGs). These are also written in Python.
Instead of encapsulating your critical transformation logic somewhere in a tool, you place it where it belongs to inside the Orchestrator.
Another advantage is using plain Python. There is no need to encapsulate other dependencies or requirements, like fetching from an FTP, copying data from A to B, writing a batch-file. You do that and everything else in the same place.
Features of Airflow
Moreover, you get a fully functional overview of all current tasks in one place.
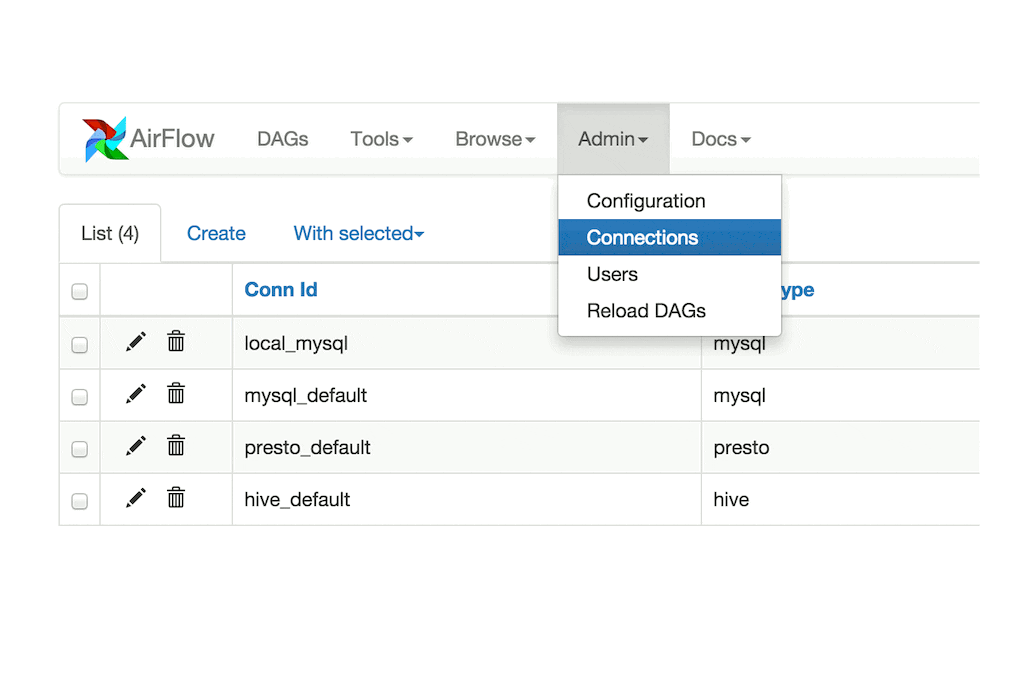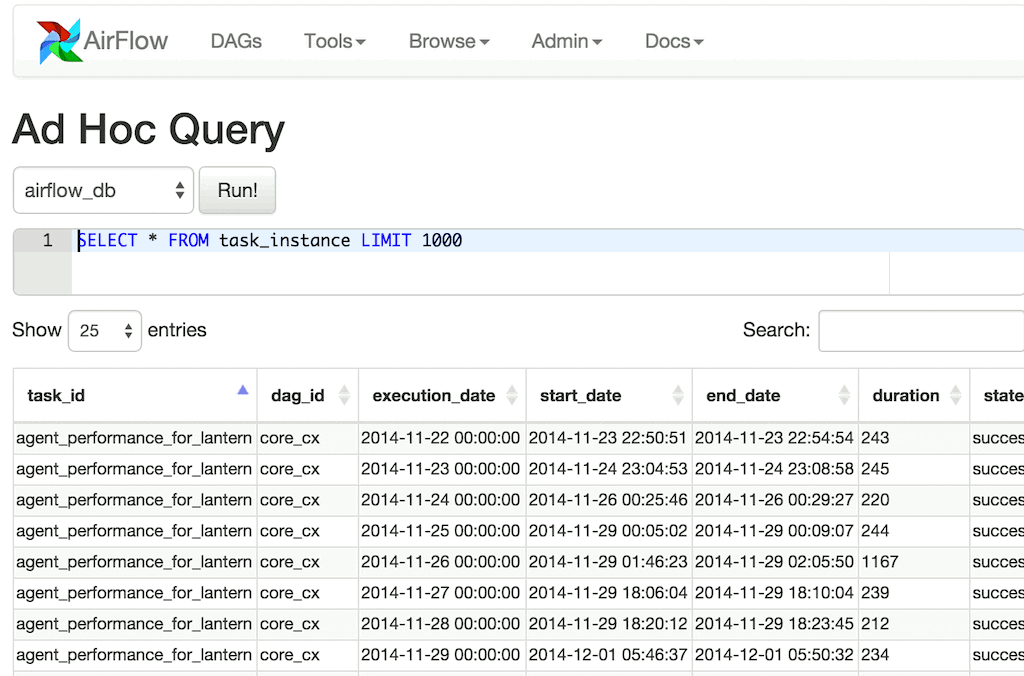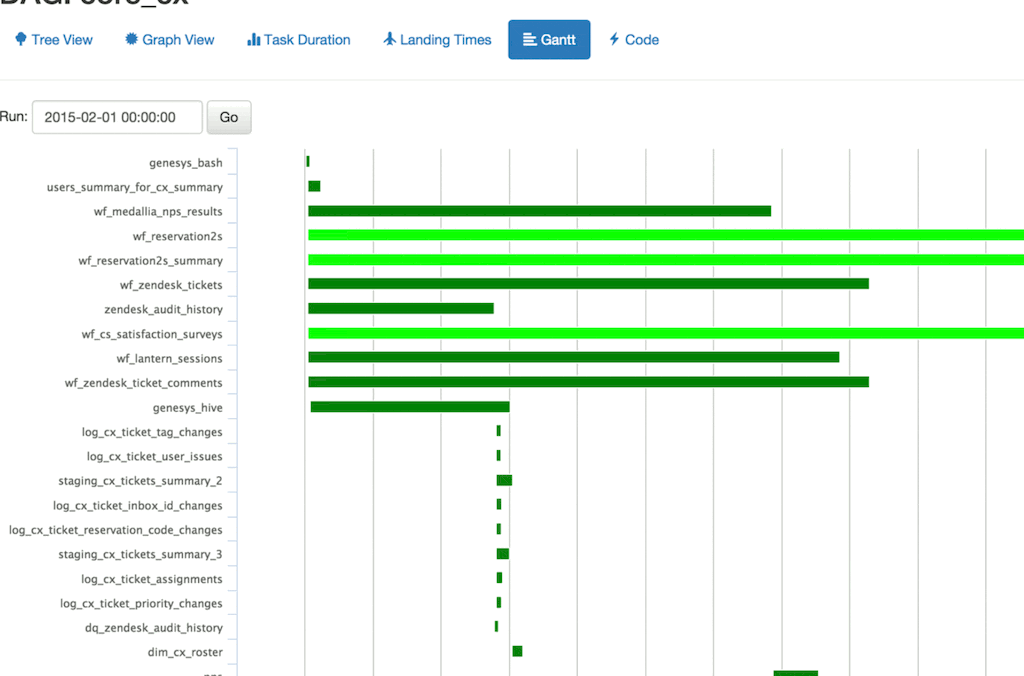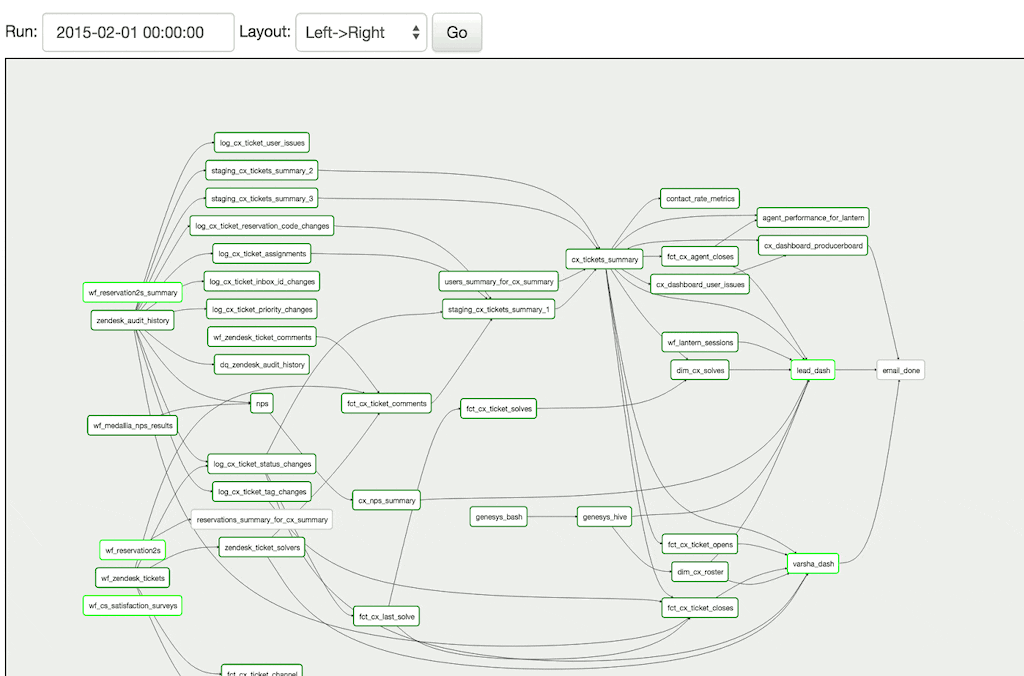
More relevant features of Airflow are that you write workflows as if you are writing programs. External jobs like Databricks, Spark, etc. are no problems.
Job testing goes through Airflow itself. That includes passing parameters to other jobs downstream or verifying what is running on Airflow and seeing the actual code. The log files and other meta-data are accessible through the web GUI.
(Re)run only on parts of the workflow and dependent tasks is a crucial feature which comes out of the box when you create your workflows with Airflow. The jobs/tasks are run in a context, the scheduler passes in the necessary details plus the work gets distributed across your cluster at the task level, not at the DAG level.
For many more feature visit the full list.
ETL with Apache Airflow
If you want to start with Apache Airflow as your new ETL-tool, please start with this ETL best practices with Airflow shared with you. It has examples simple ETL-examples, with plain SQL, with HIVE, with Data Vault, Data Vault 2, Data Vault with Big Data processes. It gives you an excellent overview of what’s possible and also how you would approach it.
At the same time, there is a Docker container that you can use, meaning you don’t even have to set-up any infrastructure, pull the container from here.
For the GitHub-repo follow the link on etl-with-airflow.
Conclusion
If you’re searching for open-source data architecture, you cannot ignore Druid for speedy OLAP responses, Apache Airflow as an orchestrator that keeps your data lineage and schedules in line, plus an easy to use dashboard tool like Apache Superset.
My experience so far is that Druid is bloody fast and a perfect fit for OLAP cube replacements in a traditional way, but still needs a more relaxed startup to install clusters, ingest data, view logs etc. If you need that, have a look at Impy which was created by the founders of Druid. It creates all the services around Druid that you need. Unfortunately, though, it’s not open-source.
Apache Airflow and its features as an orchestrator are something which has not happened much yet in traditional Business Intelligence environments. I believe this change comes very naturally when you start using open-source and more new technologies.
And Apache Superset is an easy and fast way to be up and running and showing data from Druid. There for better tools like Tableau, etc., but not for free. That’s why Superset fits well in the ecosystem if you’re already using the above open-source technologies. But as an enterprise company, you might want to spend some money in that category because that is what the users can see at the end of the day.
Related Links:
- Understanding Apache Airflow’s key concepts
- How Druid enables analytics at Airbnb
- Google launches Cloud Composer, a new workflow automation tool for developers
- A fully managed workflow orchestration service built on Apache Airflow
- Integrating Apache Airflow and Databricks: Building ETL pipelines with Apache Spark
- ETL with Apache Airflow
- What is Data Engineering and the future of Data Warehousing
- Imply - Managed Druid platform (closed-source)
- Ultra-fast OLAP Analytics with Apache Hive and Druid
Republished on LinkedIn, freeCodeCamp and Medium.
Comments
Comment by Kaibo Hao on 2019-02-25 09:01
This is a great article for the combination of the 3 open source projects. This is what I am looking for. Thanks for your help. : )
Comment by Simon on 2019-02-27 19:58
Thank you Kabio Hao, I’m glad it helped you. Let me know what you think in case you going to use it as well.
Comment by dougfoo on 2020-08-29 07:53
Love the articles on how to assemble the # of options out there today. How is Presto used in the arch here?